Documentation Restructure
This commit is contained in:
@@ -1,16 +0,0 @@
|
||||
### IP Addresses
|
||||
Documented IP addresses / MAC addresses of physical servers, containers, virtual machines, and IoT devices on the homelab network.
|
||||
|
||||
## Subnets
|
||||
### SERVER Network (192.168.3.0/24)
|
||||
|
||||
| **Hostname / Description** | **Network Interface(s)** | **IP Address** | **Status** | Link Speed |
|
||||
| :--- | :--- | :--- | :--- | :--- |
|
||||
| MOON-HOST-01 | moon-host-01-nic1 | 192.168.102.10 | Active | 10GbE Full Duplex |
|
||||
| MOON-HOST-01 | moon-host-01-nic2 | 192.168.102.20 | Broken | 10GbE Full Duplex |
|
||||
| MOON-HOST-02 | moon-host-02-nic1 | 192.168.102.30 | Active | 10GbE Full Duplex |
|
||||
| MOON-HOST-02 | moon-host-02-nic2 | 192.168.102.40 | Broken | 10GbE Full Duplex |
|
||||
| MOON-STORAGE-01 | lagg2 (ix0) | 192.168.102.50, 192.168.102.60, 192.168.102.70, 192.168.102.80 | Broken | 10GbE Full Duplex |
|
||||
| MOON-STORAGE-01 | lagg2 (ix1) | 192.168.102.50, 192.168.102.60, 192.168.102.70, 192.168.102.80 | Broken | 10GbE Full Duplex |
|
||||
| MOON-STORAGE-01 | lagg2 (ix2) | 192.168.102.50, 192.168.102.60, 192.168.102.70, 192.168.102.80 | Active | 10GbE Full Duplex |
|
||||
| MOON-STORAGE-01 | lagg2 (ix3) | 192.168.102.50, 192.168.102.60, 192.168.102.70, 192.168.102.80 | Active | 10GbE Full Duplex |
|
||||
@@ -1,7 +0,0 @@
|
||||
## VIRT-NODE-01.bunny-lab.io
|
||||
| **IP Address** | **Description** | **Interface Name** | **Device Name** |
|
||||
| :--- | :--- | :--- | :--- |
|
||||
| Disabled | iLO Port (Embedded Left) | Embedded LOM Port 1 | HPE Ethernet 1Gb 2-port 361i Adapter #2 |
|
||||
| Disabled | iLO Port (Embedded Right) | Embedded LOM Port 2 | HPE Ethernet 1Gb 2-port 361i Adapter |
|
||||
| 192.168.3.22 | 10GbE_LeftPort | Ethernet | Intel(R) Ethernet Controller X540-AT2 #4 |
|
||||
| Cluster_SET Team | 10GbE_RightPort | Ethernet | Intel(R) Ethernet Controller X540-AT2 #3 |
|
||||
@@ -1,7 +0,0 @@
|
||||
# Automations | Scripts | Playbooks
|
||||
This section of the documentation goes over concepts such as Ansible Playbooks, Bash Scripts, Batch Files, Powershell Scripts, and other useful kinds of scripts. These are used for a variety of tasks from performing backups to deploying and provisioning virtual machines.
|
||||
|
||||
!!! note
|
||||
The amount of usefulness of this section depends on how much you automate your homelab environment. You may not need this section of the homelab documentation as much as the other sections, but it is still a useful resource of quick commands / scripts to handle day-to-day tasks.
|
||||
|
||||
Use the navigation tabs at the left of this section to browse the different script-based categories.
|
||||
@@ -1 +0,0 @@
|
||||
You can deploy Keycloak via a [docker-compose stack](https://docs.bunny-lab.io/Servers/Containerization/Docker/Compose/Keycloak/) found within the "Containerization" section of the documentation.
|
||||
+2
-1
@@ -4,7 +4,7 @@ You may find that you need to be able to run playbooks on domain-joined Windows
|
||||
### Configure Windows Devices
|
||||
You will need to prepare the Windows devices to allow them to be remotely controlled by Ansible playbooks. Run the following powershell script on all of the devices that will be managed by the Ansible AWX environment.
|
||||
|
||||
- [WinRM Prerequisite Setup Script](https://docs.bunny-lab.io/Servers/Automation/Ansible/Enable%20WinRM%20on%20Windows%20Devices/)
|
||||
- [WinRM Prerequisite Setup Script](../enable-winrm-on-windows-devices.md)
|
||||
|
||||
### Create an AWX Instance Group
|
||||
At this point, we need to make an "Instance Group" for the AWX Execution Environments that will use both a Keytab file and custom DNS servers defined by configmap files created below. Reference information was found [here](https://github.com/kurokobo/awx-on-k3s/blob/main/tips/use-kerberos.md#create-container-group). This group allows for persistence across playbooks/templates, so that if you establish a Kerberos authentication in one playbook, it will persist through the entire job's workflow.
|
||||
@@ -199,3 +199,4 @@ The following playbook is an example pulled from https://git.bunny-lab.io
|
||||
msg: "Kerberos ticket successfully acquired for user {{ kerberos_user }}"
|
||||
when: kinit_result.rc == 0
|
||||
```
|
||||
|
||||
{kind=link}
|
Before Width: | Height: | Size: 122 KiB After Width: | Height: | Size: 122 KiB |
+5
-4
@@ -5,7 +5,7 @@ Deploying a Rancher RKE2 Cluster-based Ansible AWX Operator server. This can sc
|
||||
This document assumes you are running **Ubuntu Server 22.04** or later with at least 16GB of memory, 8 CPU cores, and 64GB of storage.
|
||||
|
||||
## Deploy Rancher RKE2 Cluster
|
||||
You will need to deploy a [Rancher RKE2 Cluster](https://docs.bunny-lab.io/Servers/Containerization/Kubernetes/Deployment/Rancher%20RKE2/) on an Ubuntu Server-based virtual machine. After this phase, you can focus on the Ansible AWX-specific deployment. A single ControlPlane node is all you need to set up AWX, additional infrastructure can be added after-the-fact.
|
||||
You will need to deploy a [Rancher RKE2 Cluster](../../../../platforms/containerization/kubernetes/deployment/rancher-rke2.md) on an Ubuntu Server-based virtual machine. After this phase, you can focus on the Ansible AWX-specific deployment. A single ControlPlane node is all you need to set up AWX, additional infrastructure can be added after-the-fact.
|
||||
|
||||
!!! tip "Checkpoint/Snapshot Reminder"
|
||||
If this is a virtual machine, after deploying the RKE2 cluster and validating it functions, now would be the best time to take a checkpoint / snapshot of the VM before moving forward, in case you need to perform rollbacks of the server(s) if you accidentally misconfigure something during deployment.
|
||||
@@ -89,7 +89,7 @@ You will need to create these files all in the same directory using the content
|
||||
```
|
||||
|
||||
## Ensure the Kubernetes Cluster is Ready
|
||||
Check that the status of the cluster is ready by running the following commands, it should appear similar to the [Rancher RKE2 Example](https://docs.bunny-lab.io/Containers/Kubernetes/Rancher%20RKE2/Rancher%20RKE2%20Cluster/#install-helm-rancher-certmanager-jetstack-rancher-and-longhorn):
|
||||
Check that the status of the cluster is ready by running the following commands, it should appear similar to the [Rancher RKE2 Example](../../../../platforms/containerization/kubernetes/deployment/rancher-rke2.md#install-helm-rancher-certmanager-jetstack-rancher-and-longhorn):
|
||||
```
|
||||
export KUBECONFIG=/etc/rancher/rke2/rke2.yaml
|
||||
kubectl get pods --all-namespaces
|
||||
@@ -104,7 +104,7 @@ sudo timedatectl set-timezone America/Denver
|
||||
## Deploy AWX using Kustomize
|
||||
Now it is time to tell Kubernetes to read the configuration files using Kustomize (*built-in to newer versions of Kubernetes*) to deploy AWX into the cluster.
|
||||
!!! warning "Be Patient"
|
||||
The AWX deployment process can take a while. Use the commands in the [Troubleshooting](https://docs.bunny-lab.io/Containers/Kubernetes/Rancher%20RKE2/AWX%20Operator/Ansible%20AWX%20Operator/#troubleshooting) section if you want to track the progress after running the commands below.
|
||||
The AWX deployment process can take a while. Use the commands in the [Troubleshooting](./awx-operator.md#troubleshooting) section if you want to track the progress after running the commands below.
|
||||
|
||||
If you get an error that looks like the below, re-run the `kubectl apply -k .` command a second time after waiting about 10 seconds. The second time the error should be gone.
|
||||
``` sh
|
||||
@@ -161,7 +161,7 @@ tcp:
|
||||
If you have gotten this far, you should now be able to access AWX via the WebUI and log in.
|
||||
|
||||
- AWX WebUI: https://awx.bunny-lab.io
|
||||
|
||||

|
||||
You may see a prompt about "AWX is currently upgrading. This page will refresh when complete". Be patient, let it finish. When it's done, it will take you to a login page.
|
||||
AWX will generate its own secure password the first time you set up AWX. Username is `admin`. You can run the following command to retrieve the password:
|
||||
```
|
||||
@@ -188,3 +188,4 @@ kubectl logs -n awx awx-operator-controller-manager-6c58d59d97-qj2n2 -c awx-mana
|
||||
```
|
||||
!!! note
|
||||
The `-6c58d59d97-qj2n2` noted at the end of the Kubernetes "Pod" mentioned in the command above is randomized. You will need to change it based on the name shown when running the `kubectl get pods -n awx` command.
|
||||
|
||||
+2
-1
@@ -1,7 +1,7 @@
|
||||
# Host Inventories
|
||||
When you are deploying playbooks, you target hosts that exist in "Inventories". These inventories consist of a list of hosts and their corresponding IP addresses, as well as any host-specific variables that may be necessary to declare to run the playbook. You can see an example inventory file below.
|
||||
|
||||
Keep in mind the "Group Variables" section varies based on your environment. NTLM is considered insecure, but may be necessary when you are interacting with Windows servers that are not domain-joined. Otherwise you want to use Kerberos authentication. This is outlined more in the [AWX Kerberos Implementation](https://docs.bunny-lab.io/Servers/Automation/Ansible/AWX/AWX%20Kerberos%20Implementation/#job-template-inventory-examples) documentation.
|
||||
Keep in mind the "Group Variables" section varies based on your environment. NTLM is considered insecure, but may be necessary when you are interacting with Windows servers that are not domain-joined. Otherwise you want to use Kerberos authentication. This is outlined more in the [AWX Kerberos Implementation](../awx/awx-kerberos-implementation.md#job-template-inventory-examples) documentation.
|
||||
|
||||
!!! note "Inventory Data Relationships"
|
||||
An inventory file consists of hosts, groups, and variables. A host belongs to a group, and a group can have variables configured for it. If you run a playbook / job template against a host, it will assign the variables associated to the group that host belongs to (if any) during runtime.
|
||||
@@ -32,3 +32,4 @@ ansible_port=5986
|
||||
ansible_winrm_transport=ntlm
|
||||
ansible_winrm_server_cert_validation=ignore
|
||||
```
|
||||
|
||||
+2
-1
@@ -29,7 +29,7 @@ Deployment playbooks are meant to be playbooks (or a series of playbooks forming
|
||||
- [PLACEHOLDER]()
|
||||
- [PLACEHOLDER]()
|
||||
### Kerberos
|
||||
This playbook is designed to be chain-loaded before any playbooks that involve interacting with Active Directory Domain-Joined Windows Devices. It establishes a connection with Active Directory using domain credentials, sets up a keytab file (among other things), and makes it so the execution environment that the subsequent jobs are running in are able to run against windows devices. This ensures the connection is encrypted the entire time the playbooks are running instead of using lower-security authentication methods like NTLM, which don't even always work in most circumstances. You can find more information in the [Kerberos Authentication](https://docs.bunny-lab.io/Docker%20%26%20Kubernetes/Servers/AWX/AWX%20Operator/Ansible%20AWX%20Operator/?h=awx#kerberos-implementation) section of the AWX Operator deployment documentation. `It does require additional setup prior to running the playbook.`
|
||||
This playbook is designed to be chain-loaded before any playbooks that involve interacting with Active Directory Domain-Joined Windows Devices. It establishes a connection with Active Directory using domain credentials, sets up a keytab file (among other things), and makes it so the execution environment that the subsequent jobs are running in are able to run against windows devices. This ensures the connection is encrypted the entire time the playbooks are running instead of using lower-security authentication methods like NTLM, which don't even always work in most circumstances. You can find more information in the [Kerberos Authentication](../awx/awx-kerberos-implementation.md#kerberos-implementation) section of the AWX documentation. `It does require additional setup prior to running the playbook.`
|
||||
|
||||
- [Establish_Kerberos_Connection.yml](https://git.bunny-lab.io/GitOps/awx.bunny-lab.io/src/branch/main/playbooks/Linux/Establish_Kerberos_Connection.yml)
|
||||
|
||||
@@ -53,3 +53,4 @@ Deployment playbooks are meant to be playbooks (or a series of playbooks forming
|
||||
- [PLACEHOLDER]()
|
||||
- Install BGInfo
|
||||
- [PLACEHOLDER]()
|
||||
|
||||
@@ -0,0 +1,30 @@
|
||||
# Automation
|
||||
## Purpose
|
||||
Infrastructure automation, orchestration, and workflow tooling.
|
||||
|
||||
## Includes
|
||||
- Ansible and Puppet patterns
|
||||
- Inventory and credential conventions
|
||||
- CI/CD and automation notes
|
||||
|
||||
## New Document Template
|
||||
````markdown
|
||||
# <Document Title>
|
||||
## Purpose
|
||||
<what this automation doc exists to describe>
|
||||
|
||||
!!! info "Assumptions"
|
||||
- <platform or tooling assumptions>
|
||||
- <privilege assumptions>
|
||||
|
||||
## Inputs
|
||||
- <variables, inventories, secrets>
|
||||
|
||||
## Procedure
|
||||
```sh
|
||||
# Commands or job steps
|
||||
```
|
||||
|
||||
## Validation
|
||||
- <command + expected result>
|
||||
````
|
||||
+3
-2
@@ -1,7 +1,7 @@
|
||||
**Purpose**: Puppet Bolt can be leveraged in an Ansible-esque manner to connect to and enroll devices such as Windows Servers, Linux Servers, and various workstations. To this end, it could be used to run ad-hoc tasks or enroll devices into a centralized Puppet server. (e.g. `LAB-PUPPET-01.bunny-lab.io`)
|
||||
|
||||
!!! note "Assumptions"
|
||||
This deployment assumes you are deploying Puppet bolt onto the same server as Puppet. If you have not already, follow the [Puppet Deployment](https://docs.bunny-lab.io/Servers/Automation/Puppet/Deployment/Puppet/) documentation to do so before continuing with the Puppet Bolt deployment.
|
||||
This deployment assumes you are deploying Puppet bolt onto the same server as Puppet. If you have not already, follow the [Puppet Deployment](./puppet.md) documentation to do so before continuing with the Puppet Bolt deployment.
|
||||
|
||||
## Initial Preparation
|
||||
``` sh
|
||||
@@ -176,7 +176,7 @@ klist
|
||||
### Prepare Windows Devices
|
||||
Windows devices need to be prepared ahead-of-time in order for WinRM functionality to work as-expected. I have prepared a powershell script that you can run on each device that needs remote management functionality. You can port this script based on your needs, and deploy it via whatever methods you have available to you. (e.g. Ansible, Group Policies, existing RMM software, manually via remote desktop, etc).
|
||||
|
||||
You can find the [WinRM Enablement Script](https://docs.bunny-lab.io/Docker%20%26%20Kubernetes/Servers/AWX/AWX%20Operator/Enable%20Kerberos%20WinRM/?h=winrm) in the Bunny Lab documentation.
|
||||
You can find the [WinRM Enablement Script](../../ansible/enable-winrm-on-windows-devices.md) in the Bunny Lab documentation.
|
||||
|
||||
## Ad-Hoc Command Examples
|
||||
At this point, you should finally be ready to connect to Windows and Linux devices and run commands on them ad-hoc. Puppet Bolt Modules and Plans will be discussed further down the road.
|
||||
@@ -210,3 +210,4 @@ At this point, you should finally be ready to connect to Windows and Linux devic
|
||||
Successful on 2 targets: lab-auth-01.bunny-lab.io,lab-auth-02.bunny-lab.io
|
||||
Ran on 2 targets in 0.68 sec
|
||||
```
|
||||
|
||||
+19
-2
@@ -1,2 +1,19 @@
|
||||
# Bunny Lab - Blog
|
||||
Welcome to the (experimental) blog section of my homelab documentation site. It's not really meant as a full-blown documentation augmentation, and more of a supplemental section for my current projects, thoughts, and roadblocks. More of a place to store my thoughts.
|
||||
# Blog
|
||||
## Purpose
|
||||
Narrative posts for lessons learned, experiments, and updates.
|
||||
|
||||
## New Post Template
|
||||
````markdown
|
||||
# <Post Title>
|
||||
## Context
|
||||
<why this mattered>
|
||||
|
||||
## What Changed
|
||||
- <key actions or decisions>
|
||||
|
||||
## Results
|
||||
- <what worked / what failed>
|
||||
|
||||
## Lessons Learned
|
||||
- <what you would do differently next time>
|
||||
````
|
||||
|
||||
@@ -15,7 +15,7 @@ tags:
|
||||
---
|
||||
|
||||
# Learning to Leverage Gitea Runners
|
||||
When I first started my journey with a GitOps mentality to transition a portion of my homelab's infrastructure to an "**Intrastructure-as-Code**" structure, I had made my own self-made Docker container that I called the [Git-Repo-Updater](https://docs.bunny-lab.io/Servers/Containerization/Docker/Custom%20Containers/Git%20Repo%20Updater/). This self-made tool was useful to me because it copied the contents of Gitea repositories into bind-mounted container folders on my Portainer servers. This allowed me to set up configurations for Homepage-Docker, Material MkDocs, Traefik Reverse Proxy, and others to pull configuration changes from Gitea directly into the production servers, causing them to hot-load the changes instantly. (within 10 seconds, give or take).
|
||||
When I first started my journey with a GitOps mentality to transition a portion of my homelab's infrastructure to an "**Intrastructure-as-Code**" structure, I had made my own self-made Docker container that I called the [Git-Repo-Updater](../../platforms/containerization/docker/custom-containers/git-repo-updater.md). This self-made tool was useful to me because it copied the contents of Gitea repositories into bind-mounted container folders on my Portainer servers. This allowed me to set up configurations for Homepage-Docker, Material MkDocs, Traefik Reverse Proxy, and others to pull configuration changes from Gitea directly into the production servers, causing them to hot-load the changes instantly. (within 10 seconds, give or take).
|
||||
|
||||
## Criticisms of Git-Repo-Updater
|
||||
When I made the [Git-Repo-Updater docker container stack](https://git.bunny-lab.io/container-registry/git-repo-updater), I ran into the issue of having made something I knew existing solutions existed for but simply did not understand well-enough to use yet. This caused me to basically delegate the GitOps workflow to a bash script with a few environment variables, running inside of an Alpine Linux container. While the container did it's job, it would occassionally have hiccups, caching issues, or repository branch errors that made no sense. This lack of transparency and the need to build an entire VSCode development environment to push new docker package updates to Gitea's [package repository for Git-Repo-Updater](https://git.bunny-lab.io/container-registry/-/packages/container/git-repo-updater/latest) caused a lot of development headaches.
|
||||
@@ -113,4 +113,5 @@ Then, when you push changes to a repository, the workflow's task triggers automa
|
||||
|
||||
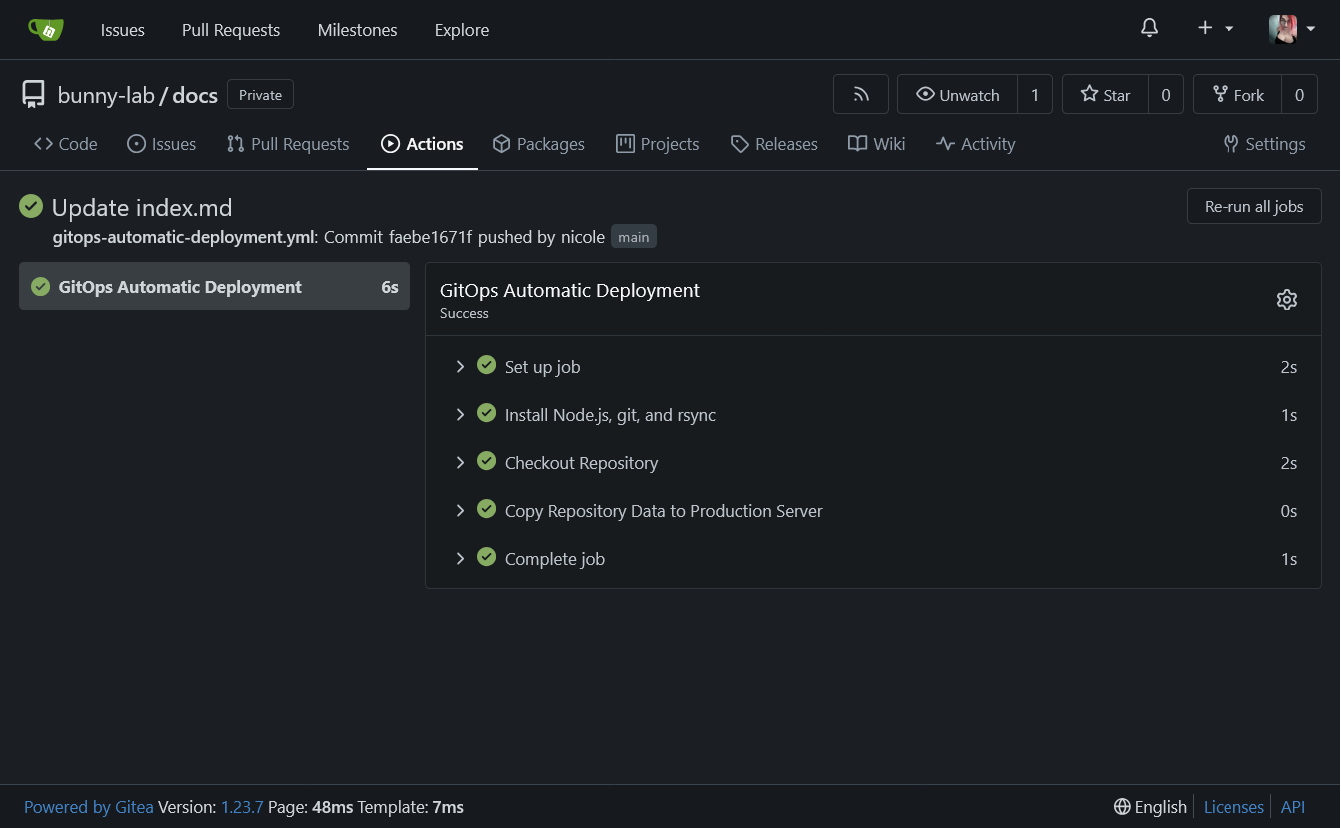
Gitea Act Runners are a beautiful thing, and it's a damn shame it took me this long to get around to learning how they work and using them.
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
@@ -5,8 +5,8 @@ updated: 2024-12-15
|
||||
authors:
|
||||
- nicole
|
||||
links:
|
||||
- Servers/Virtualization/OpenStack/Ansible Openstack.md
|
||||
- Servers/Virtualization/OpenStack/Canonical OpenStack.md
|
||||
- platforms/virtualization/openstack/ansible-openstack.md
|
||||
- platforms/virtualization/openstack/canonical-openstack.md
|
||||
categories:
|
||||
- Virtualization
|
||||
- Containers
|
||||
@@ -19,10 +19,11 @@ tags:
|
||||
So, I want to start with a little context. As part of a long-standing project I have been working on, I have tried to deploy OpenStack. OpenStack is sort of envisioned as "Infrastructure as a Service (IAAS)". Basically you deploy an OpenStack cluster, which can run its own KVM for virtual machine and containers, or it can interface with an existing Hypervisor infrastructure, such as Hyper-V. In most cases, people branch out the "Control", "Compute", and "Storage" roles into different physical servers, but in my homelab, I have been attempting to deploy it via a "Converged" model, of having Control, Compute, and Storage on each node, spanning a high-availability cluster of 3 nodes.
|
||||
|
||||
## The Problem
|
||||
The problems come into the overall documentation provided for deploying either [Canonical Openstack](https://ubuntu.com/openstack/install) which I have detailed my frustrations of the system in my own attempted re-write of the documentation [here](https://docs.bunny-lab.io/Servers/Virtualization/OpenStack/Canonical%20OpenStack/). I have also attempted to deploy it via [Ansible OpenStack](https://docs.openstack.org/project-deploy-guide/openstack-ansible/2024.1/), whereas my documentation thus far in my homelab is visible [here](https://docs.bunny-lab.io/Servers/Virtualization/OpenStack/Ansible%20Openstack/).
|
||||
The problems come into the overall documentation provided for deploying either [Canonical Openstack](https://ubuntu.com/openstack/install) which I have detailed my frustrations of the system in my own attempted re-write of the documentation [here](../../platforms/virtualization/openstack/canonical-openstack.md). I have also attempted to deploy it via [Ansible OpenStack](https://docs.openstack.org/project-deploy-guide/openstack-ansible/2024.1/), whereas my documentation thus far in my homelab is visible [here](../../platforms/virtualization/openstack/ansible-openstack.md).
|
||||
|
||||
You see, OpenStack is like icecream, it has many different ways to deploy it, and it can be as simple, or as overtly-complex as you need it to be, and it scales *really well* across a fleet of servers in a datacenter. My problems come in where the Canonical deployment has never worked fully / properly, and their own development team is hesitant to recommend the current documentation, and the Ansible OpenStack deployment process, while relatively simple, requires a base of existing knowledge that makes translating the instructions into more user-friendly instructions in my homelab documentation a difficult task. Eventually I want to automate much of the process as much as I can, but that will take time.
|
||||
|
||||
The common issue I've seen while trying to deploy OpenStack is understanding the networking, how networking is configured, network bridges, etc. The process is different based on the deployment method (Currently trying to deploy it via OpenStack Ansible). Hopefully in the near future I will make some kind of breakthrough in the deployment process and get everything working.
|
||||
|
||||
I will post an update later if I figure things out!
|
||||
|
||||
|
||||
@@ -33,6 +33,19 @@ Ordering is implicit and intentional.
|
||||
|
||||
---
|
||||
|
||||
## Core Sections (Recommended)
|
||||
Most documents should include, at minimum:
|
||||
- **Purpose** (why this doc exists)
|
||||
- **Assumptions** (platform, privileges, prerequisites)
|
||||
- **Procedure** (commands and configuration)
|
||||
|
||||
Include these when applicable:
|
||||
- **Architectural Overview** (diagram or flow)
|
||||
- **Validation** (explicit checks with expected output)
|
||||
- **Troubleshooting** → **Symptoms** / **Resolution**
|
||||
|
||||
---
|
||||
|
||||
## Headings
|
||||
- `#` — Document title (one per document)
|
||||
- `##` — Major logical phases or topics
|
||||
@@ -127,6 +140,8 @@ Validation is **mandatory** for any procedure that affects:
|
||||
|
||||
Validation lists should be explicit and testable.
|
||||
|
||||
For lower-risk or informational documents, validation is optional.
|
||||
|
||||
---
|
||||
|
||||
## Tone and Voice
|
||||
@@ -0,0 +1,40 @@
|
||||
# Foundations
|
||||
## Purpose
|
||||
Defines the baseline documentation standards, shared references, and structural conventions used everywhere else in this knowledgebase.
|
||||
|
||||
## Includes
|
||||
- Documentation styling contract
|
||||
- Inventory and naming conventions
|
||||
- Shared templates and glossary references
|
||||
|
||||
## New Document Template
|
||||
````markdown
|
||||
# <Document Title>
|
||||
## Purpose
|
||||
<one paragraph describing why this exists>
|
||||
|
||||
!!! info "Assumptions"
|
||||
- <OS / platform / privilege assumptions>
|
||||
- <required tools or prerequisites>
|
||||
|
||||
## Scope
|
||||
- <what is covered>
|
||||
- <what is explicitly out of scope>
|
||||
|
||||
## Procedure
|
||||
```sh
|
||||
# Commands go here (grouped and annotated)
|
||||
```
|
||||
|
||||
## Validation
|
||||
- <command + expected result>
|
||||
|
||||
## Troubleshooting
|
||||
### Symptoms
|
||||
- <what you see>
|
||||
|
||||
### Resolution
|
||||
```sh
|
||||
# Fix steps
|
||||
```
|
||||
````
|
||||
+12
-11
@@ -1,7 +1,7 @@
|
||||
## Overview
|
||||
All servers (physical and virtual) are documented within this specific page. They are written in a specific annotated manner in order to make them copy/paste ready for the Ansible AWX Operator server that interacts with devices in the homelab over `SSH` and `WinRM` protocols. This allows me to automate functions such as updates across the entire homelab declaratively versus individually.
|
||||
|
||||
**Note**: This list does not include Docker/Kubernetes-based workloads/servers. Those can be found within the [Container Network IP Table](https://docs.bunny-lab.io/Networking/IP%20Tables/192.168.5.0%20-%20Container%20Network/) document. Given that Ansible does not interact with containers in my homelab (*yet*), these devices are not listed within this document.
|
||||
**Note**: This list does not include Docker/Kubernetes-based workloads/servers. Those can be found within the [Container Network IP Table](../../networking/ip-tables/192-168-5-0-container-network.md) document. Given that Ansible does not interact with containers in my homelab (*yet*), these devices are not listed within this document.
|
||||
|
||||
## Updating Ansible Inventory
|
||||
Whenever changes are made here, they need to be replicated to the production Ansible AWX Inventory File. This ensures that Ansible AWX is always up-to-date. Simply copy/paste the codeblock below into the linked inventory file, and commit the change with a comment explaining what was added/removed from the inventory list.
|
||||
@@ -164,26 +164,26 @@ ansible_connection=ssh
|
||||
7. Immich Server @ `192.168.3.7` | [Documentation](https://immich.app/docs/install/docker-compose/)
|
||||
8. Zensical Documentation Server @ `192.168.3.8` | [Documentation](https://hub.docker.com/r/zensical/zensical)
|
||||
9. Not Currently In-Use @ `192.168.3.9` | [Documentation](https://example.com)
|
||||
10. Ansible AWX @ `192.168.3.10` | [Documentation](https://docs.bunny-lab.io/Servers/Automation/Ansible/AWX/Deployment/AWX%20Operator/)
|
||||
10. Ansible AWX @ `192.168.3.10` | [Documentation](../../automation/ansible/awx/deployment/awx-operator.md)
|
||||
11. Minecraft - All The Mods 9 @ `192.168.3.11` | [Documentation](https://www.curseforge.com/minecraft/modpacks/all-the-mods-9)
|
||||
12. Ferrumgate Server @ `192.168.3.12` | [Documentation](https://ferrumgate.com/)
|
||||
13. NOT IN USE @ `192.168.3.13`
|
||||
14. Minecraft - All The Mods 10 @ `192.168.3.14` | [Documentation](https://www.curseforge.com/minecraft/modpacks/all-the-mods-10)
|
||||
15. Docker Container Environment (Portainer) @ `192.168.3.15` | [Documentation](https://docs.bunny-lab.io/Servers/Containerization/Docker/Deploy%20Portainer/)
|
||||
16. Valheim Server @ `192.168.3.16` | [Documentation](https://docs.bunny-lab.io/Servers/Game%20Servers/Valheim/)
|
||||
15. Docker Container Environment (Portainer) @ `192.168.3.15` | [Documentation](../../platforms/containerization/docker/deploy-portainer.md)
|
||||
16. Valheim Server @ `192.168.3.16` | [Documentation](../../services/gaming/valheim.md)
|
||||
17. Not Currently In-Use @ `192.168.3.17` | [Documentation](https://example.com)
|
||||
18. Keycloak Server @ `192.168.3.18` | [Documentation](https://docs.bunny-lab.io/Servers/Containerization/Docker/Compose/Keycloak/)
|
||||
19. Docker Container Environment (Portainer) @ `192.168.3.19` | [Documentation](https://docs.bunny-lab.io/Servers/Containerization/Docker/Deploy%20Portainer/)
|
||||
20. PrivacyIDEA @ `192.168.3.20` | [Documentation](https://docs.bunny-lab.io/Servers/Authentication/privacyIDEA/)
|
||||
21. Puppet Server @ `192.168.3.21` | [Documentation](https://docs.bunny-lab.io/Servers/Automation/Puppet/Deployment/Puppet/)
|
||||
18. Keycloak Server @ `192.168.3.18` | [Documentation](../../services/authentication/keycloak/deployment.md)
|
||||
19. Docker Container Environment (Portainer) @ `192.168.3.19` | [Documentation](../../platforms/containerization/docker/deploy-portainer.md)
|
||||
20. PrivacyIDEA @ `192.168.3.20` | [Documentation](../../services/authentication/privacyidea.md)
|
||||
21. Puppet Server @ `192.168.3.21` | [Documentation](../../automation/puppet/deployment/puppet.md)
|
||||
22. Not Currently In-Use @ `192.168.3.22` | [Documentation](https://example.com)
|
||||
23. Hyper-V Failover Cluster @ `192.168.3.23` | [Documentation](https://docs.bunny-lab.io/Servers/Virtualization/Hyper-V/Failover%20Cluster/Deploy%20Failover%20Cluster%20Node/)
|
||||
23. Hyper-V Failover Cluster @ `192.168.3.23` | [Documentation](../../platforms/virtualization/hyper-v/failover-cluster/deploy-failover-cluster-node.md)
|
||||
24. TrueNAS SCALE @ `192.168.3.24` | [Documentation](https://www.truenas.com/truenas-scale/)
|
||||
25. Primary Domain Controller @ `192.168.3.25` | [Documentation](https://example.com)
|
||||
26. Secondary Domain Controller @ `192.168.3.26` | [Documentation](https://example.com)
|
||||
27. Blue Iris Surveillance @ `192.168.3.27` | [Documentation](https://blueirissoftware.com/)
|
||||
28. ARK: Survival Ascended Server @ `192.168.3.28` | [Documentation](https://docs.bunny-lab.io/Servers/Game%20Servers/ARK%20-%20Survival%20Ascended/)
|
||||
29. Nextcloud AIO @ `192.168.3.29` | [Documentation](https://docs.bunny-lab.io/Servers/Containerization/Docker/Compose/Nextcloud-AIO/)
|
||||
28. ARK: Survival Ascended Server @ `192.168.3.28` | [Documentation](../../services/gaming/ark-survival-ascended.md)
|
||||
29. Nextcloud AIO @ `192.168.3.29` | [Documentation](../../services/productivity/nextcloud-aio.md)
|
||||
30. Dev-Testing Win11 Lab Environment @ `192.168.3.35` | [Documentation](https://example.com)
|
||||
31. Windows 11 Work VM @ `192.168.3.31` | [Documentation](https://example.com)
|
||||
32. Matrix Synapse HomeServer @ `192.168.3.32` | [Documentation](https://github.com/matrix-org/synapse)
|
||||
@@ -232,3 +232,4 @@ ansible_connection=ssh
|
||||
75. Rancher Harvester Cluster VIP
|
||||
253. Fedora Workstation 42 VM
|
||||
254. Windows 11 Workstation
|
||||
|
||||
@@ -0,0 +1,30 @@
|
||||
# Hardware
|
||||
## Purpose
|
||||
Physical assets, node inventories, storage layouts, and power topology for the lab.
|
||||
|
||||
## Includes
|
||||
- Node build sheets and inventory
|
||||
- Disk arrays and drive replacement procedures
|
||||
- Power and UPS mapping
|
||||
|
||||
## New Document Template
|
||||
````markdown
|
||||
# <Document Title>
|
||||
## Purpose
|
||||
<what this hardware doc exists to describe>
|
||||
|
||||
!!! info "Assumptions"
|
||||
- <hardware model / firmware / OS assumptions>
|
||||
- <privilege assumptions>
|
||||
|
||||
## Inventory
|
||||
- <serials, bays, disks, NICs, etc>
|
||||
|
||||
## Procedure
|
||||
```sh
|
||||
# Commands (if applicable)
|
||||
```
|
||||
|
||||
## Validation
|
||||
- <command + expected result>
|
||||
````
|
||||
+3
-2
@@ -5,7 +5,7 @@ This document acts as a workflow to understand how to replace a drive on TrueNAS
|
||||
- You will log into the TrueNAS Core [WebUI](http://192.168.3.3).
|
||||
- Navigate to "**Storage > Disks**"
|
||||
- Look for the drive that is having issues / faults / unavailable and reference it's `da` number to reference later. (e.g. `da3`)
|
||||
- Confirm the serial number of the drive and correlate that to the physical location in the [Disk Arrays](https://docs.bunny-lab.io/Hardware/Storage%20Node%2001%20%28TrueNAS%20Core%29/Disk%20Arrays/) document,
|
||||
- Confirm the serial number of the drive and correlate that to the physical location in the [Disk Arrays](./disk-arrays.md) document,
|
||||
- Navigate to "**Storage > Pools**"
|
||||
- Look for the gear icon to the right of the storage pool and click on it
|
||||
- Click on "**Status**"
|
||||
@@ -15,7 +15,7 @@ This document acts as a workflow to understand how to replace a drive on TrueNAS
|
||||
### Physical Disk Replacement
|
||||
At this point, we need to physically go to the server and pull out the failing drive and replace it.
|
||||
|
||||
- Take note of the new serial number on the replacement drive and update the [Disk Arrays](https://docs.bunny-lab.io/Hardware/Storage%20Node%2001%20%28TrueNAS%20Core%29/Disk%20Arrays/) document accordingly.
|
||||
- Take note of the new serial number on the replacement drive and update the [Disk Arrays](./disk-arrays.md) document accordingly.
|
||||
- Insert the replacement drive back into the TrueNAS Core server
|
||||
|
||||
### Trigger Disk Re-Scan
|
||||
@@ -36,3 +36,4 @@ Now we need to tell TrueNAS / FreeBSD to re-scan all disks to locate the new one
|
||||
```sh
|
||||
zpool status | grep "to go"
|
||||
```
|
||||
|
||||
@@ -1,55 +1,36 @@
|
||||
# Home
|
||||
## 🏡 Homelab Documentation Structure
|
||||
|
||||
This documentation details the design, setup, and day-to-day management of my personal homelab environment. The content is shared to benefit others exploring similar projects, from newcomers to advanced users. Topics range from initial hardware choices to complex network and automation workflows.
|
||||
|
||||
!!! info "General Purpose"
|
||||
- Provides a transparent look into my homelab architecture.
|
||||
- Share practical guides, workflows, and lessons learned.
|
||||
- Help others adapt and improve their own setups.
|
||||
## Homelab Documentation Structure
|
||||
This documentation details the design, setup, and day-to-day management of my homelab environment. The goal is to keep it deterministic, CLI-first, and easy to audit or reproduce.
|
||||
|
||||
---
|
||||
|
||||
## 📂 What You’ll Find Here
|
||||
This site is organized into several main areas:
|
||||
## Top-Level Sections
|
||||
**Foundations**
|
||||
- Conventions, templates, glossary, and shared standards
|
||||
|
||||
**Hardware**
|
||||
|
||||
- Rack and device inventory
|
||||
- Storage solutions (disk arrays, NAS, SSD/HDD, etc.)
|
||||
- UPS and power management
|
||||
- Node build sheets, storage layouts, and physical inventory
|
||||
|
||||
**Networking**
|
||||
- Addressing plans, firewall rules, VPNs, and network services
|
||||
|
||||
- Physical and virtual network topology
|
||||
- VLAN, subnets, and IP management
|
||||
- Firewall and security rules
|
||||
- Docker and container network configurations
|
||||
**Platforms**
|
||||
- Virtualization and containerization stacks (hypervisors, Kubernetes, Docker)
|
||||
|
||||
**Servers & Virtualization**
|
||||
**Services**
|
||||
- Deployable apps and services (auth, docs, email, monitoring, etc.)
|
||||
|
||||
- Host OS installation and hardening
|
||||
- Proxmox, Docker, Kubernetes deployment notes
|
||||
- VM/container orchestration
|
||||
- Infrastructure-as-Code
|
||||
**Automation**
|
||||
- Ansible, Puppet, and workflow automation notes
|
||||
|
||||
**Automation & Monitoring**
|
||||
**Operations**
|
||||
- Runbooks for maintenance, backups, and troubleshooting
|
||||
|
||||
- Ansible playbooks and workflows
|
||||
- Monitoring stacks (Prometheus, Grafana, etc.)
|
||||
- Alerting and log management
|
||||
**Reference**
|
||||
- Quick scripts and snippets for day-to-day tasks
|
||||
|
||||
**Application Services**
|
||||
|
||||
- Self-hosted applications and deployment strategies
|
||||
- Reverse proxies, SSL, and SSO integration
|
||||
- Routine maintenance and update automation
|
||||
|
||||
**General Tips & Reference**
|
||||
|
||||
- Command-line snippets and troubleshooting
|
||||
- Backups, recovery, and disaster planning
|
||||
- Migration notes and lessons learned
|
||||
**Blog**
|
||||
- Narrative posts and lessons learned
|
||||
|
||||
---
|
||||
|
||||
@@ -59,17 +40,15 @@ This site is organized into several main areas:
|
||||
- **Personal Environment:** These docs reflect my own environment, goals, and risk tolerance.
|
||||
- **Security & Scale:** Approaches described here are suited to homelab or SMB use, and may need adjustments for enterprise-scale, regulatory compliance, or higher security standards.
|
||||
- **No Credentials:** All sensitive info is redacted or generalized.
|
||||
- **Assumptions:** Some guides assume the use of specific tools, e.g. [Portainer](https://docs.bunny-lab.io/Docker%20%26%20Kubernetes/Servers/Docker/Portainer/), [AWX](https://docs.bunny-lab.io/Docker%20%26%20Kubernetes/Servers/AWX/AWX%20Operator/Ansible%20AWX%20Operator/), etc. Substitute with your preferred tools as needed.
|
||||
- **Assumptions:** Some guides assume specific tools, e.g. [Portainer](./platforms/containerization/docker/deploy-portainer.md), [AWX](./automation/ansible/awx/deployment/awx-operator.md), etc. Substitute with your preferred tools as needed.
|
||||
|
||||
---
|
||||
|
||||
## ✨ Quick Start
|
||||
|
||||
- Use the navigation panel to explore categories or search for keywords.
|
||||
- Each section is designed to be as modular and self-contained as possible.
|
||||
- Feedback and suggestions are always welcome!
|
||||
- Each section is designed to be modular and self-contained.
|
||||
- Feedback and suggestions are always welcome.
|
||||
|
||||
---
|
||||
|
||||
> _“Homelabs are for learning, breaking things, and sharing the journey. Hope you find something helpful here!”_
|
||||
|
||||
|
||||
@@ -0,0 +1,30 @@
|
||||
# Networking
|
||||
## Purpose
|
||||
Network topology, addressing, firewalling, VPN, and network service dependencies.
|
||||
|
||||
## Includes
|
||||
- IP tables and address plans
|
||||
- Firewall and VPN configurations
|
||||
- Network controllers and DNS-related services
|
||||
|
||||
## New Document Template
|
||||
````markdown
|
||||
# <Document Title>
|
||||
## Purpose
|
||||
<what this network doc exists to describe>
|
||||
|
||||
!!! info "Assumptions"
|
||||
- <platform or appliance assumptions>
|
||||
- <privilege assumptions>
|
||||
|
||||
## Architecture
|
||||
<ASCII diagram or concise topology notes>
|
||||
|
||||
## Procedure
|
||||
```sh
|
||||
# Commands or config steps
|
||||
```
|
||||
|
||||
## Validation
|
||||
- <command + expected result>
|
||||
````
|
||||
@@ -0,0 +1,35 @@
|
||||
# Operations
|
||||
## Purpose
|
||||
Runbooks for maintenance, troubleshooting, backups, and day-2 operations.
|
||||
|
||||
## Includes
|
||||
- Backup and DR workflows
|
||||
- Routine maintenance tasks
|
||||
- Troubleshooting runbooks
|
||||
|
||||
## New Document Template
|
||||
````markdown
|
||||
# <Document Title>
|
||||
## Purpose
|
||||
<what this runbook exists to solve>
|
||||
|
||||
!!! warning "Risk"
|
||||
- <irreversible actions or data impact>
|
||||
|
||||
## Procedure
|
||||
```sh
|
||||
# Commands or steps (grouped and annotated)
|
||||
```
|
||||
|
||||
## Validation
|
||||
- <command + expected result>
|
||||
|
||||
## Troubleshooting
|
||||
### Symptoms
|
||||
- <what you see>
|
||||
|
||||
### Resolution
|
||||
```sh
|
||||
# Fix steps
|
||||
```
|
||||
````
|
||||
+2
-1
@@ -1,4 +1,4 @@
|
||||
**Purpose**: Docker container running Alpine Linux that automates and improves upon much of the script mentioned in the [Git Repo Updater](https://docs.bunny-lab.io/Scripts/Bash/Git%20Repo%20Updater) document. It offers the additional benefits of checking for updates every 5 seconds instead of every 60 seconds. It also accepts environment variables to provide credentials and notification settings, and can have an infinite number of monitored repositories.
|
||||
**Purpose**: Docker container running Alpine Linux that automates and improves upon much of the script mentioned in the [Git Repo Updater](../../../../reference/bash/git-repo-updater.md) document. It offers the additional benefits of checking for updates every 5 seconds instead of every 60 seconds. It also accepts environment variables to provide credentials and notification settings, and can have an infinite number of monitored repositories.
|
||||
|
||||
### Deployment
|
||||
You can find the current up-to-date Gitea repository that includes the `docker-compose.yml` and `.env` files that you need to deploy everything [here](https://git.bunny-lab.io/container-registry/-/packages/container/git-repo-updater/latest)
|
||||
@@ -104,3 +104,4 @@ while true; do
|
||||
done
|
||||
|
||||
```
|
||||
|
||||
+2
-1
@@ -47,9 +47,10 @@ Alternative Methods:
|
||||
2. Be sure to set the `-v /srv/containers/portainer:/data` value to a safe place that gets backed up regularily.
|
||||
|
||||
### Configure Docker Network
|
||||
I highly recomment setting up a [Dedicated Docker MACVLAN Network](https://docs.bunny-lab.io/Docker%20%26%20Kubernetes/Docker/Docker%20Networking/). You can use it to keep your containers on their own subnet.
|
||||
I highly recomment setting up a [Dedicated Docker MACVLAN Network](../../../networking/docker-networking/docker-networking.md). You can use it to keep your containers on their own subnet.
|
||||
|
||||
### Access Portainer WebUI
|
||||
You will be able to access the Portainer WebUI at the following address: `https://<IP Address>:9443`
|
||||
!!! warning
|
||||
You need to be quick, as there is a timeout period where you wont be able to onboard / provision Portainer and will be forced to restart it's container. If this happens, you can find the container using `sudo docker container ls` proceeded by `sudo docker restart <ID of Portainer Container>`.
|
||||
|
||||
+3
-2
@@ -2,7 +2,7 @@
|
||||
You may be comfortable operating with Portainer or `docker-compose`, but there comes a point where you might want to migrate those existing workloads to a Kubernetes cluster as easily-as-possible. Lucklily, there is a way to do this using a tool called "**Kompose**'. Follow the instructions seen below to convert and deploy your existing `docker-compose.yml` into a Kubernetes cluster such as Rancher RKE2.
|
||||
|
||||
!!! info "RKE2 Cluster Deployment"
|
||||
This document assumes that you have an existing Rancher RKE2 cluster deployed. If not, you can deploy one following the [Deploy RKE2 Cluster](https://docs.bunny-lab.io/Servers/Containerization/Kubernetes/Deployment/Rancher RKE2/) documentation.
|
||||
This document assumes that you have an existing Rancher RKE2 cluster deployed. If not, you can deploy one following the [Deploy RKE2 Cluster](./deployment/rancher-rke2.md) documentation.
|
||||
|
||||
We also assume that the cluster name within Rancher RKE2 is named `local`, which is the default cluster name when setting up a Kubernetes Cluster in the way seen in the above documentation.
|
||||
|
||||
@@ -214,7 +214,7 @@ If you were able to successfully verify access to the service when talking to it
|
||||
!!! info "Section Considerations"
|
||||
This section of the document does not (*currently*) cover the process of setting up health checks to ensure that the load-balanced server destinations in the reverse proxy are online before redirecting traffic to them. This is on my to-do list of things to implement to further harden the deployment process.
|
||||
|
||||
This section also does not cover the process of setting up a reverse proxy. If you want to follow along with this document, you can deploy a Traefik reverse proxy via the [Traefik](https://docs.bunny-lab.io/Servers/Containerization/Docker/Compose/Traefik/) deployment documentation.
|
||||
This section also does not cover the process of setting up a reverse proxy. If you want to follow along with this document, you can deploy a Traefik reverse proxy via the [Traefik](../../../services/edge/traefik.md) deployment documentation.
|
||||
|
||||
With the above considerations in-mind, we just need to make some small changes to the existing Traefik configuration file to ensure that it load-balanced across every node of the cluster to ensure high-availability functions as-expected.
|
||||
|
||||
@@ -265,3 +265,4 @@ With the above considerations in-mind, we just need to make some small changes t
|
||||
|
||||
!!! success "Verify Access via Reverse Proxy"
|
||||
If everything worked, you should be able to access the service at https://ntfy.bunny-lab.io, and if one of the cluster nodes goes offline, Rancher will automatically migrate the load to another cluster node which will take over the web request.
|
||||
|
||||
@@ -0,0 +1,30 @@
|
||||
# Platforms
|
||||
## Purpose
|
||||
Virtualization and containerization platforms, cluster builds, and base OS images.
|
||||
|
||||
## Includes
|
||||
- Hypervisors and virtualization stacks
|
||||
- Kubernetes and Docker foundations
|
||||
- Base image and cluster provisioning patterns
|
||||
|
||||
## New Document Template
|
||||
````markdown
|
||||
# <Document Title>
|
||||
## Purpose
|
||||
<what this platform doc exists to describe>
|
||||
|
||||
!!! info "Assumptions"
|
||||
- <OS / platform version>
|
||||
- <privilege assumptions>
|
||||
|
||||
## Architectural Overview
|
||||
<ASCII diagram or concise flow>
|
||||
|
||||
## Procedure
|
||||
```sh
|
||||
# Commands (grouped and annotated)
|
||||
```
|
||||
|
||||
## Validation
|
||||
- <command + expected result>
|
||||
````
|
||||
+2
-1
@@ -15,7 +15,7 @@ You will need to download the [Proxmox VE 8.1 ISO Installer](https://www.proxmox
|
||||
```
|
||||
|
||||
1. This tells Hyper-V to allow the GuestVM to behave as a hypervisor, nested under Hyper-V, allowing the virtualization functionality of the Hypervisor's CPU to be passed-through to the GuestVM.
|
||||
2. This tells Hyper-V to allow your GuestVM to have multiple nested virtual machines with their own independant MAC addresses. This is useful when using nested Virtual Machines, but is also a requirement when you set up a [Docker Network](https://docs.bunny-lab.io/Containers/Docker/Docker%20Networking/) leveraging MACVLAN technology.
|
||||
2. This tells Hyper-V to allow your GuestVM to have multiple nested virtual machines with their own independant MAC addresses. This is useful when using nested Virtual Machines, but is also a requirement when you set up a [Docker Network](../../../networking/docker-networking/docker-networking.md) leveraging MACVLAN technology.
|
||||
|
||||
### Networking
|
||||
You will need to set a static IP address, in this case, it will be an address within the 20GbE network. You will be prompted to enter these during the ProxmoxVE installation. Be sure to set the hostname to something that matches the following FQDN: `proxmox-node-01.MOONGATE.local`.
|
||||
@@ -149,3 +149,4 @@ reboot
|
||||
Setting up alerts in Proxmox is important and critical to making sure you are notified if something goes wrong with your servers.
|
||||
|
||||
https://technotim.live/posts/proxmox-alerts/
|
||||
|
||||
@@ -0,0 +1,61 @@
|
||||
# Git Repo Updater (Script)
|
||||
## Purpose
|
||||
Standalone `repo_watcher.sh` script used by the Git Repo Updater container. This script clones or pulls one or more repositories and rsyncs them into destination paths.
|
||||
|
||||
For the containerized version and deployment details, see the [Git Repo Updater container doc](../../platforms/containerization/docker/custom-containers/git-repo-updater.md).
|
||||
|
||||
## Script
|
||||
```sh
|
||||
#!/bin/sh
|
||||
|
||||
# Function to process each repo-destination pair
|
||||
process_repo() {
|
||||
FULL_REPO_URL=$1
|
||||
DESTINATION=$2
|
||||
|
||||
# Extract the URL without credentials for logging and notifications
|
||||
CLEAN_REPO_URL=$(echo "$FULL_REPO_URL" | sed 's/https:\/\/[^@]*@/https:\/\//')
|
||||
|
||||
# Directory to hold the repository locally
|
||||
REPO_DIR="/root/Repo_Cache/$(basename $CLEAN_REPO_URL .git)"
|
||||
|
||||
# Clone the repo if it doesn't exist, or navigate to it if it does
|
||||
if [ ! -d "$REPO_DIR" ]; then
|
||||
curl -d "Cloning: $CLEAN_REPO_URL" $NTFY_URL
|
||||
git clone "$FULL_REPO_URL" "$REPO_DIR" > /dev/null 2>&1
|
||||
fi
|
||||
cd "$REPO_DIR" || exit
|
||||
|
||||
# Fetch the latest changes
|
||||
git fetch origin main > /dev/null 2>&1
|
||||
|
||||
# Check if the local repository is behind the remote
|
||||
LOCAL=$(git rev-parse @)
|
||||
REMOTE=$(git rev-parse @{u})
|
||||
|
||||
if [ "$LOCAL" != "$REMOTE" ]; then
|
||||
curl -d "Updating: $CLEAN_REPO_URL" $NTFY_URL
|
||||
git pull origin main > /dev/null 2>&1
|
||||
rsync -av --delete --exclude '.git/' ./ "$DESTINATION" > /dev/null 2>&1
|
||||
fi
|
||||
}
|
||||
|
||||
# Main loop
|
||||
while true; do
|
||||
# Iterate over each environment variable matching 'REPO_[0-9]+'
|
||||
env | grep '^REPO_[0-9]\+=' | while IFS='=' read -r name value; do
|
||||
# Split the value by comma and read into separate variables
|
||||
OLD_IFS="$IFS" # Save the original IFS
|
||||
IFS=',' # Set IFS to comma for splitting
|
||||
set -- $value # Set positional parameters ($1, $2, ...)
|
||||
REPO_URL="$1" # Assign first parameter to REPO_URL
|
||||
DESTINATION="$2" # Assign second parameter to DESTINATION
|
||||
IFS="$OLD_IFS" # Restore original IFS
|
||||
|
||||
process_repo "$REPO_URL" "$DESTINATION"
|
||||
done
|
||||
|
||||
# Wait for 5 seconds before the next iteration
|
||||
sleep 5
|
||||
done
|
||||
```
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user